

记录了2024年关于AI使用的一些真实场景,包括在解放生产力、效率提升、数据安全等方面的一些应用。
一部分是重复的工作,这部分彻底摒弃了人为去实现;一部分是复杂的数据处理部分,让AI实现,有些工作需要多个AI完成和调教。
一,最简单的结果搜索工作
日常中的搜索任务,都用AI替代了,例如工作生活在一些盲点,需要用到百度或者google搜索基本都被AI替代;
用AI进行内容搜索的好处是答案精准,弊端就是AI的输入词也就是所谓的提示词(prompt)需要精而简,废话不能多,但是该说的也不能落下,例如当前需要搜索一个答案:
搜索引擎:如何能够更快速的阅读文章且不容易忘记其内容?
AI提示词:你现在是一个已经阅读了上万本书的阅读超级爱好者,请以你的经验告诉我如何在阅读的过程中能够更加快速,且在快速的同时能够更容易记住书中的内容,希望你能够提供一些通俗且有效的方法给我,尽可能详细一些。
结果:

然而,可以通过AI替代搜索引擎,精准的获得自己想要的答案或者知识。这个案例通常用到的模型有ChatGPT、腾讯元宝、Gemini和X的Grok。虽然都属于通用大模型,但是在文字垂直领域表现的很不错。
二,长文档的归纳、总结和脑图的生成。
将一篇非常冗长的文档直接扔给大模型,让他帮你总结大纲和要点知识。对于200页以上的文章总结和归纳可省时省力,对想要的知识点更有目标性的获知。大模型不仅解析了文章中的内容,然后对文章的内容进行了推理,提取了哪些是重点,哪些是纲要,一一列举,提升效率的小能手。
这里的文章格式可以是PDF、doc、MarkDown、PPT等格式,还可以是一个超链接,AI可以解析超链接并且对超链接中的内容进行推理且输出。
这里用到的大模型有:
腾讯ima,google的AIStudio(集成Gemini),ChatGPT,智谱。
case:


三,长文档的翻译。
对于经常做文献翻译的人也许是一个福音,可以对500页及其以上的外文文档进行翻译。或者可以翻译为外文文档的大模型。
大模型翻译跟日常的翻译软件翻译不同的是,大模型能够理解上下午,可更加准确地翻译当前场景中用到的字词句,包括语境、专业方向等,而不是单纯的翻译文字。
这里用到的大模型有Gemini、x-doc、DeepSeek。这里Gemini是1.5pro版本,可在AIStudio中直接使用,背靠google也是翻译最准确的大模型了。deepseek是国产开源大模型,价格便宜且速度快,而且准确,性价比之王。
x-doc可以将翻译后的文档以文件的形式输出,并且文件格式可与源文件格式保持一致。
case:

四,文本翻译、推理、修改等。
场景1:翻译SRT文本
大模型:DeepSeek、Gemini、ChatGPT、腾讯元宝等,Claude应该也不错,不过目前账户还没有注册成功。
将一段文本中的部分内容进行翻译,并且按照原格式进行输出,这里翻译了一段SRT(歌词/字幕)格式的文件。以下这个案例就能明白搜索引擎/翻译工具跟人工智能的最大不同之处。首先翻译了一段字幕,但是不是我想要的形式,因为不方便查看又不方便复制用时,然后又加了一些其他需求,“输出到黑板中方便复制”,就这么完成了…


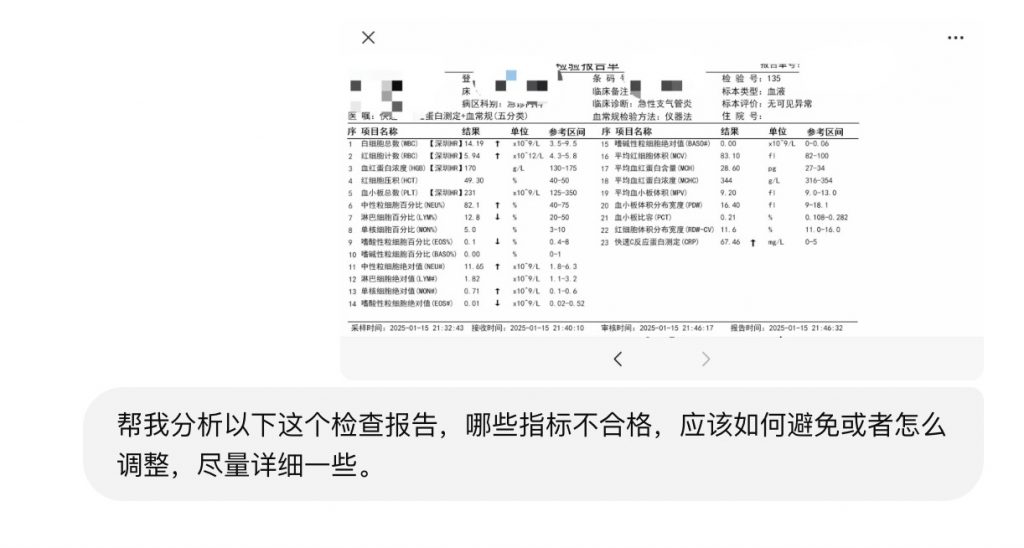
场景2:OCR及逻辑推理,前段时间有一同事去体检化验,化验报告里边的的一直指标都看不懂,然后我将报告扔给了AI,几十秒出结果,并且告诉你哪些指标正常、哪些偏高、哪些指标异常,应该怎么缓解、建议如何应对等意义列举出来了。
这里用到了GPT-4,Gemini等大模型的推理。
case:

场景3:文件生成(代码形式生成原型图等)。
用代码生成html格式的原型图,也是目前我用到最多的功能了。
通过提示词的描述和调整,告诉AI你想实现什么样的UI界面(原型)、跳转逻辑(UE)以及一些系统图表(DATA);包括系统架构图以及系统的数据设计图、模型图(MODEL)等。
这里用到了vs+cline+deepseek或者vs+Github Copilot,或cursor。
deepseek需要创建Api Key,Github Copilot和cursor仅需要账号就能操作。
case:

接下来就通过提示词让AI实现你想要的UI效果及点击跳转等,case:
提示词1:
“创建一个新的HTML项目,需求为: 1,整个html项目主要是为了做原型图而使用,并非那么精细; 2,页面和页面之间需要有跳转逻辑; 3,创建js、css、index.html文件,再创建image目录。”
提示词2:
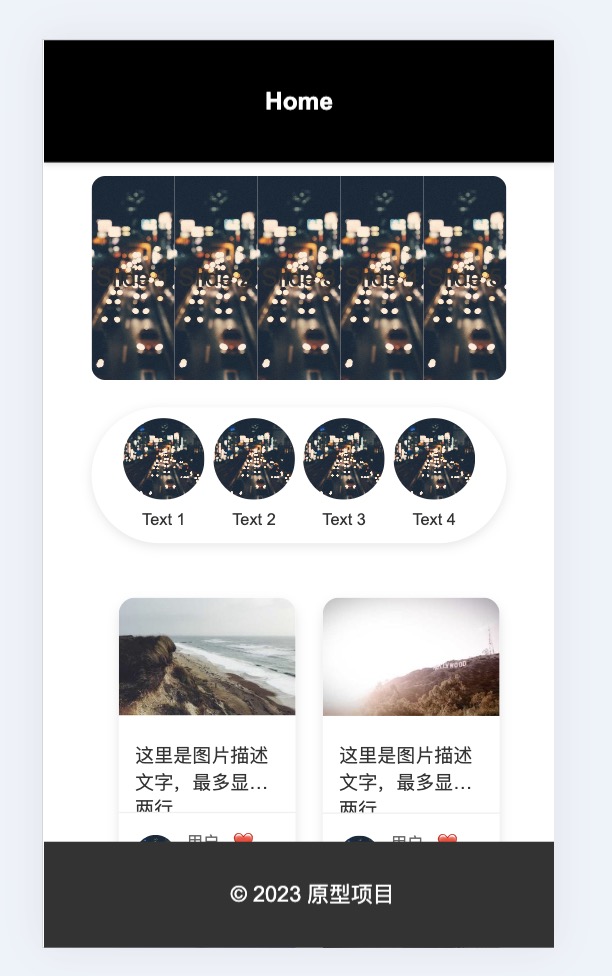
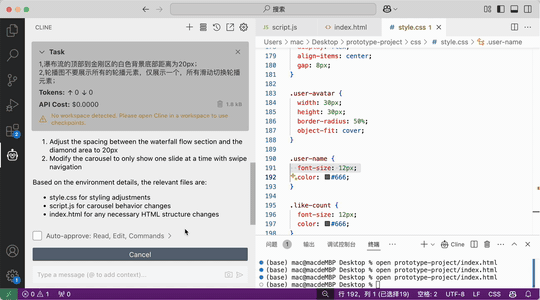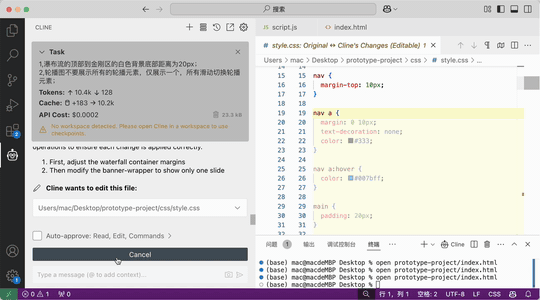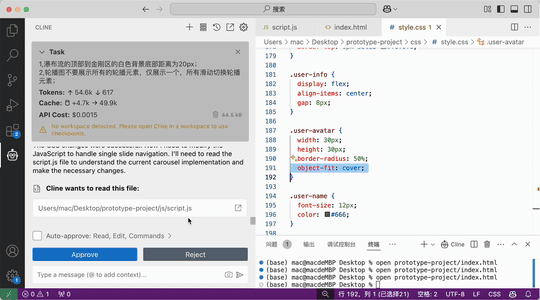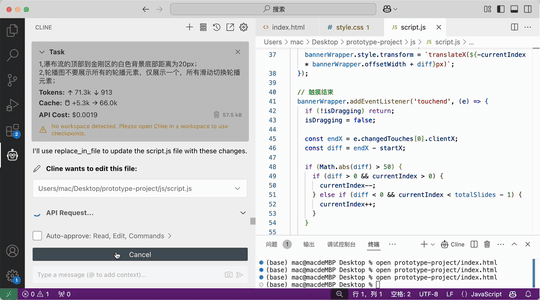
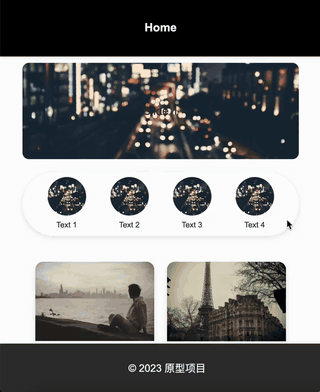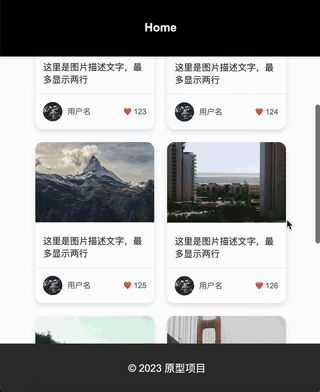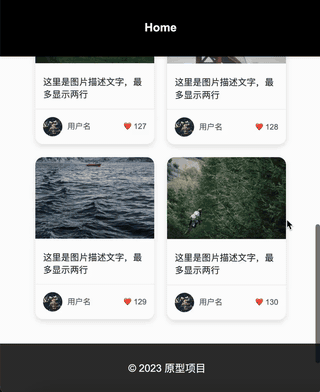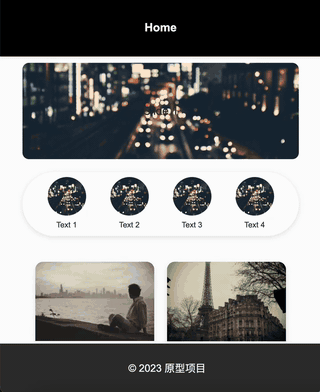
“在金刚区下边显示一个瀑布流,瀑布流汇总的元素有: 1,白色背景,需要圆角且外阴影; 2,图片,显示在白色背景上; 3,图片下方有文字描述,最多两行; 3,文字描述下方显示一个用户头像和昵称,要求在白色背景的左下方; 4,字描述下方显示一个点赞数量,要求在白色背景的右下方;”
效果:
一下是通过二十分钟左右调教AI设计出来的一个原型图:
目前代码生成需要收费,包括deepseek或者cursor。其实上手很简单,就是提示词工程量比较大,最重要的是精而简。
既要让大模型理解,又不能让大模型误解。
deepseek目前比较便宜,cursor一个月20美金,deepseek请求了一百多次才几毛钱,价格很便宜。
工具:cursor,trae,vs+cline;
// //一个产品经理原型图的提示词工程: 你是一位经验丰富的 UI/UX 设计师,同时精通前端开发。请帮我设计一个高保真原型图,要求如下: 1. **项目背景**:设计一个名为“[应用名称]”的 [平台类型,例如 iOS 或 Android] 移动应用,主要目标用户是 [用户画像,例如年轻白领],核心功能包括:[功能列表,例如注册、登录、内容浏览、消息推送等]。 2. **页面要求**: - **整体风格**:现代、简洁、符合 [平台名称] 设计规范,使用圆角元素及渐变色。 - **首页**:展示应用核心信息,包含顶部状态栏(模拟真实设备状态)、醒目的标题和轮播图。 - **详情页**:信息清晰排列,支持图文混排,附带操作按钮。 - **导航**:使用底部 Tab Bar 或侧边栏,提供快速切换不同页面的入口。 3. **技术实现**: - 生成的原型代码为 HTML 文件,使用 [Tailwind CSS/Bootstrap] 进行样式处理。 - 每个界面应作为单独的 HTML 文件存放,并在 index.html 中通过 iframe 嵌入展示所有页面,而非页面跳转。 - 图片资源尽可能使用真实图片(推荐使用 Unsplash 或 Pexels 的高质量图片),不要使用占位符图片。 4. **交互细节**: - 模拟真实的设备尺寸(例如 iPhone 15 Pro),页面元素布局合理。 - 所有按钮和输入框需具备点击和输入效果(可添加简单的 CSS 动画)。 请输出完整的 HTML 和 CSS 代码,确保代码可以直接运行并展示完整的原型图效果。 // //
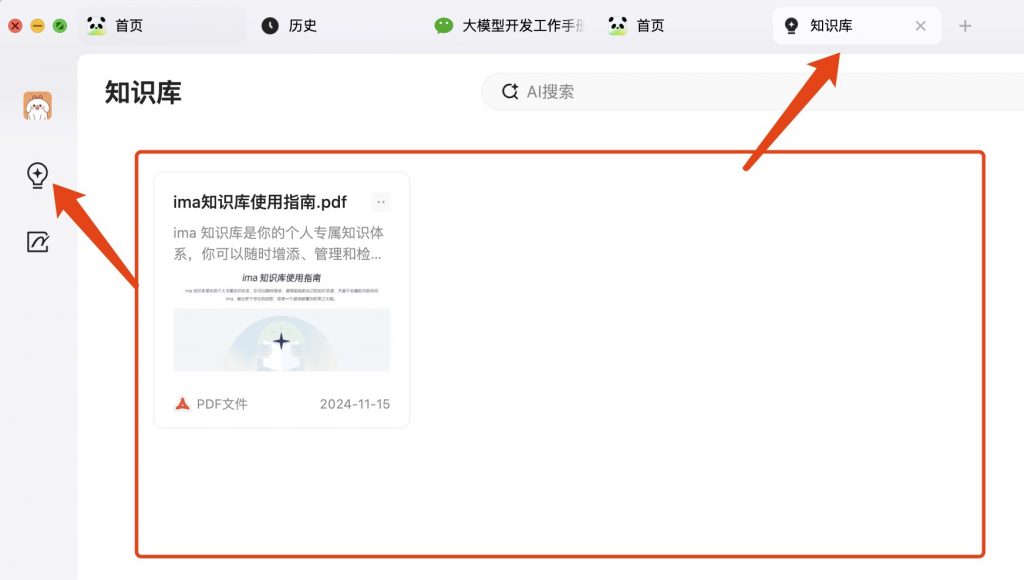
五,个人知识库;
个人知识库是一个很有用的东西,就像一个容器似的,记录自己的所有知识及表达方式的一个数据库。
案例:可以将自己平生阅读的所有书籍笔记做成一个知识库,当每次查询东西的时候可以在自己的知识库中查询和总结;
作用:
1,快速的查询和总结自己已有的只是;
2,知识的积累和沉淀;
3,根据自身的习惯、偏好回答一些问题;
4,可以根据自身的语言偏好做一些自动化的功能,例如自动回复邮件、待办事项等信息的处理,将它变成自己的个人小助理;
目前市场中大部分的AGI都能搭建自己的知识库,只不过需要一些技术的要求,例如本地大模型的环境搭建、网络大模型的话需要会一些API的接入、数据的格式化(json、markdown等);
推荐一个可视化的软件,可以很简单地创建自己的知识库,腾讯的ima,[https://ima.qq.com/],可将自己的知识库添加到ima里边,通过腾讯的元宝大模型进行查询、推理、生成等,非常方便。
个人知识库的原理其实就是,通过市场上已经训练好的大模型去查询、推理自己上传的内容,生成新的内容。
联网需要配置个人知识库的大模型通常的步骤:
1,申请大模型的网络API;
2,将自己的知识进行格式化为某一个模型所需的格式;
3,如果知识数据存在本地,需要复杂一点的存储格式,例如数据库,通过API调用本地数据进行查询和推理;如果知识需要上传到网络,那么需要通过工具或者API将格式化的数据上传到网络;
4,通过调用API输出或者通过工具的使用,输出查询和推理后的内容;
六,音频解析;
前言:音频的解析涉及到了AGI领域了,真正的AGI看了真的让人害怕,因为AI已经能将所有的事情做了,人类还需要做什么呢。有时候了解的领域知识越多越害怕。
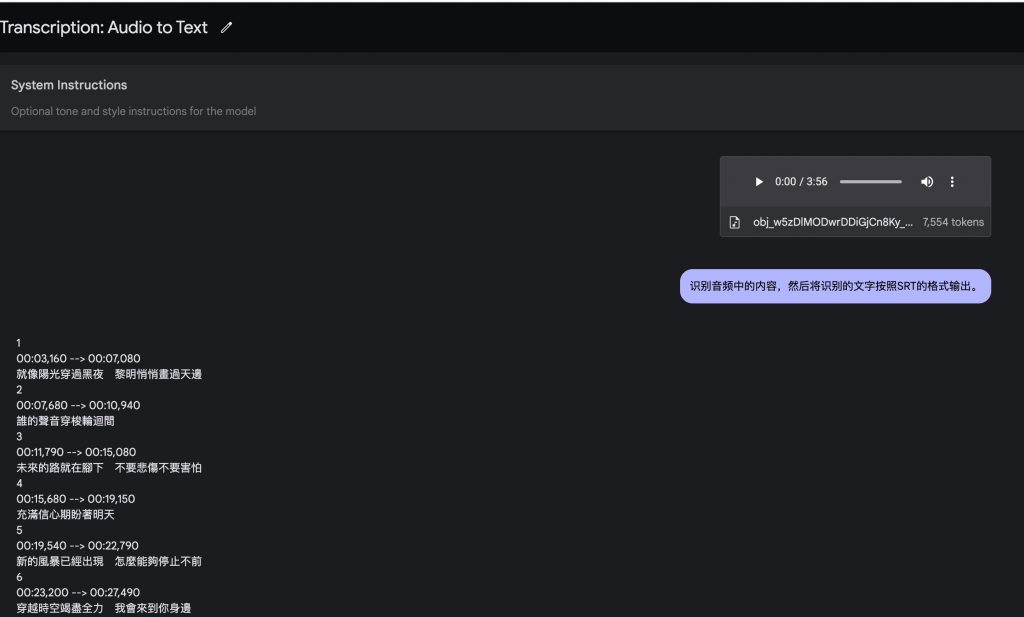
1,语音识别和格式化:OpenAI开源了音频识别并格式化工具whisper,可通过本地部署识别音频并且进行SRT化的一个工具,识别效率根据自己的硬件而定,识别结果准确定很不错,一些人为听不清的音频都能进行识别,如下图6-1为whisper的识别结果。
此工具最大的用途是可以提取音视频中的内容以文字的形式输出,对于那些影视工作者或者视频编辑人员非常友好,不需要自己再手动添加字幕,可以通过此工具进行识别,然后再找一个AI进行语境的调整和修改,就可以直接添加字幕到视频中。
2,AI Studio:
个人觉着是自己用过最强大的AI了, 真正的AGI,这个条目说音频,就拿音频来说:
(1),音频识别、推理:
先说说流程节点:
上传音频(实时录制音频)- 识别音频 – 解析音频内容 – 根据音频中的内容进行推理 – 实现推理后的结果
通俗的讲一个场景:打开AI Studio后,打开麦克风,告诉Studio,也就是开始对话了
人类:“今天身体有点不舒服”;
AI:具体哪里不舒服,您可以说出来我可以帮助您排查。
人类:稍微一着凉就会咳嗽,而且感觉咳嗽的时候肺部有点不舒服。
AI:好的,这种情况我可以一一告知您是什么状况,应该怎么预防和防护以及治疗;
AI:原因1 – 方案1
AI:原因2 – 方案2
AI:原因3 – 方案3
(2),音频识别、推理翻译:
上传音频 – 解析音频内容 – 生成想要的格式文本(RST 、json,md等)- 翻译 – 输出
AI Studio功能特别强大,集合的Google所有的AI功能于一身,这里的AGI表现为音频的解析、推理然后配合文本的生成和输出,也是AGI的主要用途之一;
以上whisper所完成的人物,AI Studio也可以完成,可以将音视频可以直接丢给AI Studio,让其解析、推理生成我们想要的内容。
今天丢给了AI Studio一个视频,让Studio通过解析生成视频中所要的效果图,关于产品开发方面的,用了一分钟不到就生成了,效果也不错。
AI Studio还能通过获取语音中的内容,通过语音告知大模型下一步要做的动作,以音频内容作为输入,可以输出图片、文字、其他动作(创建文件夹、文件)及内容,这种形式也就AGI的最标准的表现形式了。

八,文生图、图生图\扩图、图片处理(清晰化处理、图片着色等)
文生图现在有很多模型,包括本地部署的、网络的等,而且都比较成熟:
本地:
Flux,开源的文生图大模型,配合ComfyUI工作流生成图片,网络上已经有很多调教好的lora,可以直接用。
1,x grok效果很不错,而且没有任何因素的限制,任何东西都能生成,并且不需要在乎版权;
2,国内比较好的模型就是字节的即梦,不仅可以文生图、还能生成海报、最后可以将图生成视频,效果很好;
3,国内快手的kling,问生图效果也很好,不仅可以文生图,还可以进行在线试衣功能;
3,腾讯的元宝、阿里的通义、字节的豆包(没用过)应该都是可以进行文生图的。
4,国外的一些domoai、krea、开源的flux、sana等都不错。
目前文生图的场景主要用于:[1],海报;[2],自媒体封面制作;[3],自媒体视频素材;
扩图功能目前知道的有:
1,字节的即梦;
2,通义千问中有扩图智能体;
3,Diffusers Image Outpaint;
图片清晰化处理:
ESRGAN,可在设备端本地进行部署;
图片着色:
阿里DDColor:
https://www.modelscope.cn/models/iic/cv_ddcolor_image-colorization/summary
https://replicate.com/piddnad/ddcolor
扩图功能、图片清晰化处理、图片着色主要是针对日常中图片的一些处理,并不是必须使用的长期功能、相信以后得AI结合硬件设备(手机、电脑)之后,这些功能都会自带并且免费使用,下图为文生图的一张示例:
问生图是大模型表现出AGI效果最普遍且最初始的功能,输出的结果已经相当成熟,目前国内外大厂的AGI都有问生图功能,也算是基础功能了。
问生图如今用到大部分社交媒体软件,为了匹配文案或者发布动态使用。

图片编辑:
工具:即梦、ChatGPT、Gemini,这几个都比较强;
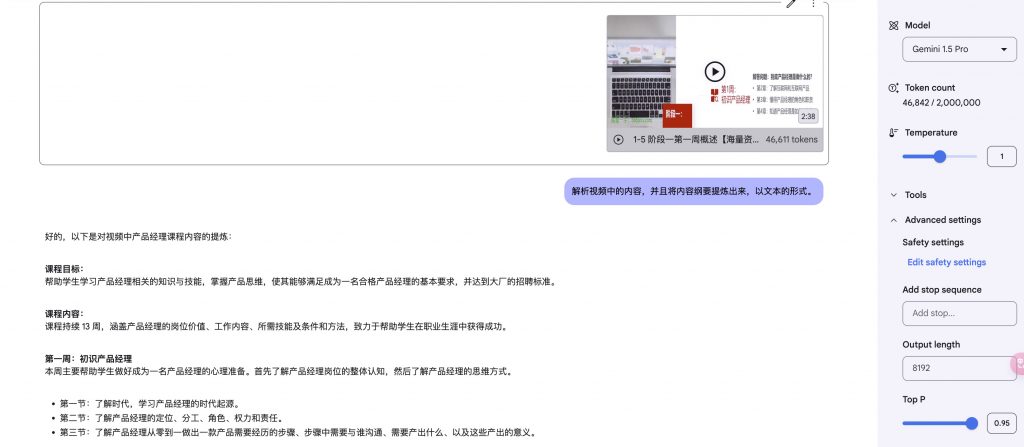
七,视频解析、归纳总结
场景:在视频特长且不想去观看,且想知道视频里边讲的内容或者主要知识点,就用到了这个功能。
流程节点:上传一段视频(也可以是长视频)给大模型,大模型通过解析、推理,然后输出视频中的纲要、知识点,也可能生成知识脑图。
1,这里推荐360浏览器,可以进行视频解析及大纲的提取;
2,Gemini;
视频解析及推理是AGI比较高级的表现了,也是AIG想象中的神态。这里的视频不仅仅是上传的视频,也可以是实时录制的视频流。
大模型对于视频的处理更加消耗资源,包括硬件及耗电方面;所以目前视频的解析支持的模型多,但是大多不开放使用。
推荐google Gemini,非常好用。
九,视频生成;
从24年年初sora的预发布到年中各大厂商视频生成模型的大爆发,24年可谓是百花争艳的一年。
背景:其中OpenAI年底发布的sora不及用户预期,效果没有宣传的那么好。且google也放出了veo2的生成片,比sora的效果好太多。或许在多模态方面google已经不在落后OpenAI。
国外的
国外目前第一梯队的模是:runway
年中国内的几家公司分别发布了自己的视频大模型,效果已经赶超了sora,属于世界第一梯队了,包括:
快手的kling,目前是文生视频最好的模型;
海螺AI,效果也很好,跟kling不相上下;
pixverse.ai,生成速度快,效果也不差;
字节跳动的即梦,效果也很好;
其他的包括:阿里的通义、腾讯的元宝都在24年相继发布了自己的视频模型;豆包应该也有,这个没用过。
生成模式:目前视频生成的模式有3中,文生视频、图生视频、视频生视频(转换源视频风格)。
场景:目前视频生成的场景对于单个用户来说几乎为0,对于企业或者团队来说还是有用的,例如一些产品的宣传视频,需要通过Domo AI生成图片,然后再通过图片生成视频,外加各种调教和修复才能成片,对于个人来说成本有点高。
所以目前在产品宣传领域、电影制作领域用到文生视频的场景多一些,其他基本没有什么应用场景,在应用场景有待发觉的同时,也需要大模型生成视频的效果越来越逼真,对于物理世界的理解越来越真实。
以下是通过即梦生成的一张动态海报视频:
十,AGI;
何为AGI,就是类人的大模型,也就是所谓的通用大模型。脱俗的讲,就是跟人类智力水平相当的大模型,人类能干什么,他就能干什么。
目前AI的能力尚未达到AGI的水平,不过目前留给人类的时间也不多了,因为大模型很快就能达到AGI的水平。目前OpenAI、google、微软、meta,国内的阿里、腾讯、字节他们的模型发展方向都是AGI方向。
从一开始的文本识别、总结、推理,到后面多模态的发展,如音乐的生成、音频的识别、推理,到后边的图片、视频的识别、推理、生成等,无一不展现出AI的发展速度,从文本到多模态的发展仅仅大约是一年时间,如果从25年开始到真正的AGI实现,可能用不了三年时间。
有时候AI工具用着用着,自己都有点害怕,害怕AI不仅仅能帮人类提高效率,害怕的是真正有一天替代人类,那么人类的还需要做什么?
从年底的动态来看,包括国内外的所有科技公司都押注到AI领域,宁愿花几百到千亿美金建设自己的计算中心来训练AI,说明AI时代已经到来。这是历史的趋势,就跟当时的移动互联网一样,只不过大模型的研发要比移动互联网时代门槛高很多,包括芯片成本、技术人员成本、后期的应用场景及推广。
目前从我自身的应用和浅显的理解,当下的AI就能彻底替代很多人的工作,包括翻译人员、文员。医疗领域和教育领域不会全被被替代,但是如果这些领域如果有了AI赋能,或许医疗队伍和师资团队至少能够减少1/10的人员,因为AI比人好用。
按照现阶段发展的现状来说,AI的应用不会全面在国内铺开来使用,也是为了社会稳定、平复之间的差距、就业率等等。
十一,API系列;
通过获取API,配置到相应的工具,实现多模态的输入输出。
场景:
1,翻译插件,配置了deepseek;
2,代码生成工具,配置了deepseek;
3,某些翻译工具, 配置了gemini1.5pro;
自由度更高,也能通过API部署自己的大模型应用,虽然大模型师其他厂商的,嗲用API而已。
目前大模型的token已经相当便宜,年中OpenAI降价、年底deepseek的横空出世以及国内阿里字节等大模型的token都降价,有的降了150%。
笼统的讲,可能拥有10000用户量的AI应用,一年的API费用也超不过2000块,至少比服务器便宜很多。
使用:去各大厂商大模型开放平台注册账户、然后申请key就能使用,没技术也可以用。
https://aistudio.google.com/apikey
https://platform.deepseek.com/api_keys
十二,一些集成AI软件的推荐;
1,Notion,强大的笔记代办事项工具,现在可以通过AI自动生成格式化的文案、流程图、表格、头脑风暴等。
2,vscode,这个就不用多提;
3,飞书,AI加持后的强大无与伦比,包括总结、表格生成、数据处理等。
结尾的感觉和告诫:
1,拥抱AI,一定要拥抱,如何拥抱,就从使用开始[使用他、接受他、依赖他、拥抱他];
2,提示词工程其实也是一个比较复杂且严谨的技术语言,还是那句老话,“既要让大模型理解,又不能让大模型误解。”;
3,多用、多想、多对比,可能会减少你很多时间成本,从而间接地增加了你的其他资产;
如转载请注明出处!