

1,Whisper+GPT(DeepSeek)做音视频双语字幕;
2,GPT/DeepSeek/AI Studio+Xmind做脑图;
3,AI总结视频纲要的核心流程和技术;
4,google gemini2.0对于视频的理解和推理属于最强,对画面的识别和推理,目前对于流媒体的处理大部分原因取决于算力,而不是技术;
5,AI智能体如何创建和训练?
AI的一些学习和思考:
一,DeepSeek的推理问题;
1,DeepSeek-R1的推理模型输出时不能消除推理模块,如果不想让其推理,用V3模型。
2,DeepSeek-R1的推理部分可以通过Prompt的严谨性去减少推理的长度。例如:
(1),原始:1+1等于几?
(2),优化后:1+1等于几,仅通过数学算数的方式进行回答即可。
二,DeepSeek的输入缓存命中问题;
1,缓存命中时针对用户输入时的提示词进行缓存的,如果用户问了一个问题,然后相同的问题再向大模型问第二遍,那么系统会通过磁盘中的缓存直接输出第一次问时候的答案;
2,缓存命中对输入提示词有很强的要求,例如标点符号的不同或者空格的多少,都会影响缓存命中机制,具体如何命中需要看deepseek官方文档;
3,缓存命中后通常都是从缓存磁盘中读取然后输出,这样减少了重复计算、节省了GPU资源、输出速度很快。
三、大模型的反省和纠错能力具体表现在哪里?
1,反省:指模型识别错误的能力;
2,纠正:指模型修改错误的能力;
反省和纠错的目的:大模型的反省和纠错通常是在同一时间执行的,所以反省和依旧的目的就是让大模型的输出具有更高的准确性。
纠错的两种反省和纠错方式:
1,被动:通过用户的反馈,引导大模型反省和纠错;
被动模式:
(1)用户提出一个问题,大模型回答错误;
(2)用户引导大模型,告诉大模型这个答案是错的;
(3)大模型反省并纠错,输出;
2,主动:主动纠错,包括知识库匹配和推理时会反省和纠错。
(1),知识库检查和匹配通常在通用大模型中,当用户提出问题后,大模型会回答一个错误的答案,但是在这个过程中又去匹配参数中的其他知识(反省过程),发现是错误的,紧接着会输出正确的答案(纠错过程)。
(2),推理大模型在推理的过程中,会进行反省和纠错,通常推理会有推理过程,在推理过程中可以看到大模型的反省和纠错的整个过程。
总结:大模型不是真人,它的「反省」本质是靠海量数据训练出的「概率匹配」,而不是真正的思考。
推理大模型的本质仍然是基于概率的迭代优化。但它通过复杂的设计和训练技巧,让这种概率匹配过程模拟出了类似人类推理的行为。推理是概率的“高级包装”。
如下图,为大模型推理的整个流程节点:
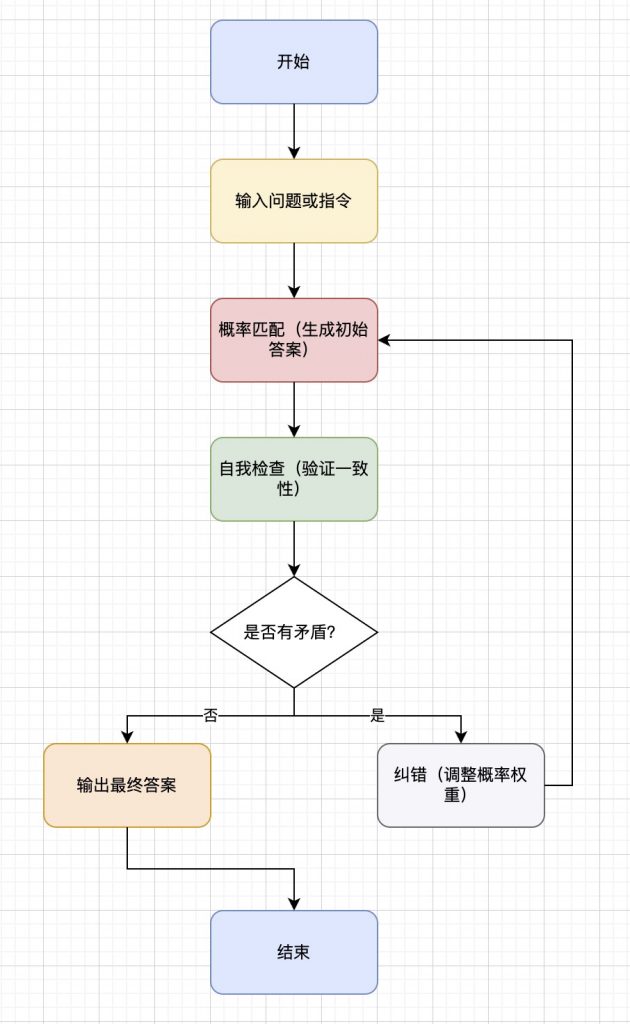
四,大模型的基础能力指什么,为什么大模型的基础能力强、基础知识扎实很重要?
五,Deep Research是什么,具体能干什么?
Deep Research是深度研究的一种工具,利用网络爬虫与搜索工具,外加大模型等其他内容整合工具形成的一款实现高效的信息整合与报告生成的工具。
可以理解成生成学术报告的一个AI智能体。
Deep Research 可以从多个网站、数据库和文献中提取信息,并将其整合成一份全面的报告。
Deep Research的作用:
1,搜索和爬取的知识或者文献内容通常都是专业的、内容安全问题;
2,可以将多个网站、数据库或者文献中的信息进行提取并整合;
3,生成一份全面的分析报告,很详细、且给予使用者一些决策上的建议(最重要)。
比如,如果你需要了解某个行业的最新趋势,它可以在几分钟内为你提供市场分析、历史数据和专家观点。然后基于数据出分析报告。
以下,就是用过Deep Research生成的一份关于iOS在各国所占份额的报告:
# # 全球十大发达经济体(按GDP) – 智能手机OS份额、语言学习兴趣及移动渗透增长 ## 各国数据概览 | 国家 | iOS 市场份额 | Android 市场份额 | 语言学习兴趣(人口比例) | 移动渗透率变化(2013→2023) | |------|-------------|------------------|--------------------------|--------------------------| | **美国 (USA)** | ~58% iOS vs 42% Android | 同左 | 高:70%的人后悔失去外语能力(表明有强烈的提升意愿) | 56% → 82%(↑26 个百分点) | | **日本** | ~69% iOS vs 31% Android | 同左 | 高:超过50%的人希望学习英语 | ~30% → 79%(↑~50 个百分点) | | **德国** | ~39% iOS vs 60% Android | 同左 | 高:86%的欧洲人认为每个人都应至少掌握一门外语(强烈的语言学习态度) | 40% → 82%(↑42 个百分点) | | **英国 (UK)** | ~52% iOS vs 47% Android | 同左 | 中等-高:约73%的人对语言学习感兴趣(仅27%“完全无兴趣”) | 62% → 82%(↑20 个百分点) | | **法国** | ~35% iOS vs 64% Android | 同左 | 高:86%(欧洲平均水平)支持多语言学习,英语被广泛认为很重要 | 42% → 83%(↑40 个百分点) | | **意大利** | ~30% iOS vs 69% Android | 同左 | 高:86%(欧洲平均水平)支持语言学习,1/4的人后悔没学习更多语言 | 41% → 85%(↑44 个百分点) | | **加拿大** | ~60% iOS vs 40% Android | 同左 | 中等:多数人双语(英语/法语),对第三语言的兴趣上升(暂无最新数据) | 56% → ~80%(↑~24 个百分点,估算值,与美国相似) | | **韩国** | ~24% iOS vs 76% Android | 同左 | 中等:英语教育重点较强,约40%的青少年正在学习英语 | 73% → ~95%(↑ ~22 个百分点 – 2013年已接近饱和) | | **澳大利亚** | ~55% iOS vs 45% Android | 同左 | 中等:~70%的人认为学习外语有价值(英语占主导,但对亚洲语言的兴趣增长) | 65% → ~85%(↑ ~20 个百分点,估算值,高智能手机普及率) | | **西班牙** | ~20% iOS vs 79% Android | 同左 | 高:88%的西班牙人曾在学校学习外语(如英语),对语言学习有浓厚文化兴趣 | 55% → ~85%(↑ ~30 个百分点,估算值,接近西欧国家) | --- # 全球十大新兴经济体(按GDP) – (ChatGPT可用性考虑) ## 各国数据概览 | 国家 | iOS 市场份额 | Android 市场份额 | 语言学习兴趣(显著数据) | 移动渗透率变化(2013→2023) | |------|-------------|------------------|--------------------------|--------------------------| | **中国** *(ChatGPT 受限)* | ~24% iOS vs 75% Android | 同左 | **极高**:数亿人正在学习英语(但ChatGPT无法正式访问) | 47% → 68%(↑21 个百分点) | | **印度** | ~4% iOS vs 95% Android | 同左 | **高**:英语在许多学校是必修课,80%的人认为英语有助于提高收入 | ~5% → 46%(↑ ~41 个百分点,智能手机普及率大幅上升) | | **巴西** | ~18% iOS vs 82% Android | 同左 | **高**:英语需求极大,仅~5%的人会英语,但大多数人认为是关键技能 | 26% → 67%(↑40 个百分点) | | **俄罗斯** *(ChatGPT 受限)* | ~30% iOS vs 69% Android | 同左 | **中等**:英语学习普遍(学校必修),兴趣存在,但ChatGPT可用性不确定 | 36% → 74%(↑38 个百分点) | | **墨西哥** | ~24% iOS vs 76% Android | 同左 | **高**:强烈希望学习英语以获取美国工作机会,~50%的学生在学校学习英语 | 37% → 62%(↑25 个百分点) | | **印度尼西亚** | ~12% iOS vs 88% Android | 同左 | **高**:英语被视为关键技能,政府推动提高英语水平 | <30% → 68%(↑ ~40 个百分点) | | **土耳其** | ~15% iOS vs 85% Android(估算) | 同左 | **高**:英语高度重视(学校普及);80%认为英语有助于就业 | 30% → 75%(↑45 个百分点) | | **沙特阿拉伯** | ~24% iOS vs 76% Android | 同左 | **中等**:英语广泛教授,92%的人拥有智能手机(多数人已双语) | 73% → ~95%(↑ ~22 个百分点,早期普及,接近饱和) | | **南非** | ~16% iOS vs 83% Android | 同左 | **高**:多语言社会,英语和南非荷兰语与本地语言并行,文化上鼓励学习其他语言 | 40% → ~60%(↑ ~20 个百分点,估算值,稳步增长) | | **阿根廷** | ~12% iOS vs 88% Android | 同左 | **高**:对英语兴趣浓厚(阿根廷在拉美国家中英语水平最高) | 31% → ~70%(↑ ~39 个百分点,估算值,智能手机普及率迅速上升) | --- # 结论与建议 基于上述数据,针对 **ChatGPT 驱动的 iOS 语言翻译应用**,首选市场应具备 **高iOS用户基数** 和 **强烈的语言学习需求**,并且 **ChatGPT 可正常访问**。从这个角度来看: ## **首选市场** - **日本、美国、英国、加拿大、澳大利亚** 是最佳目标市场: - **iOS 份额高(50-60%+)** - **语言学习需求旺盛**(如日本的iPhone占主导,同时对英语学习兴趣极大) - **智能手机渗透率高(均已超80%)** ## **次级市场** - **墨西哥、巴西**: - **Android 仍占主导,但iPhone用户基数庞大** - **学习英语的需求极高** - **ChatGPT 可用** ## **较低优先级** - **中国、俄罗斯**: - **中国 iOS 市场较小,且 ChatGPT 无法正常访问** - **俄罗斯 iOS 份额适中,但 ChatGPT 访问存在不确定性** 综上所述,推荐**首要聚焦iOS普及率高、语言学习需求强的市场**(如日本、西方国家),然后再扩展到**iPhone用户众多且英语需求大的发展中市场**(如墨西哥、巴西)。这一策略可确保产品在**iOS平台覆盖度高、用户需求匹配度强的地区**推出,提高用户接受度及增长潜力。 #